
中国团队推世界最大多模态数据集“Infinity-MM”....
在人工智能领域,数据集的规模和质量一直是推动技术进步的关键因素。近日,一个由中国多家机构组成的研究团队宣布了一个重大突破:他们成功创建了“Infinity-MM”,目前最大规模的公开多模态AI数据集之一,并在此基础上训练出了一款性能卓越的小型新模型——Aquila-VL-2B。

“Infinity-MM”数据集的构成与特点
“Infinity-MM”数据集的构成体现了其多样性和丰富性,包含四大类数据:1000万条图像描述、2440万条一般视觉指令数据、600万条精选高质量指令数据,以及300万条由GPT-4和其他AI模型生成的数据。这一数据集的创建,不仅在数量上达到了前所未有的规模,而且在质量上也通过特殊的分类系统确保了数据的质量和多样性。
Aquila-VL-2B模型的创新与性能
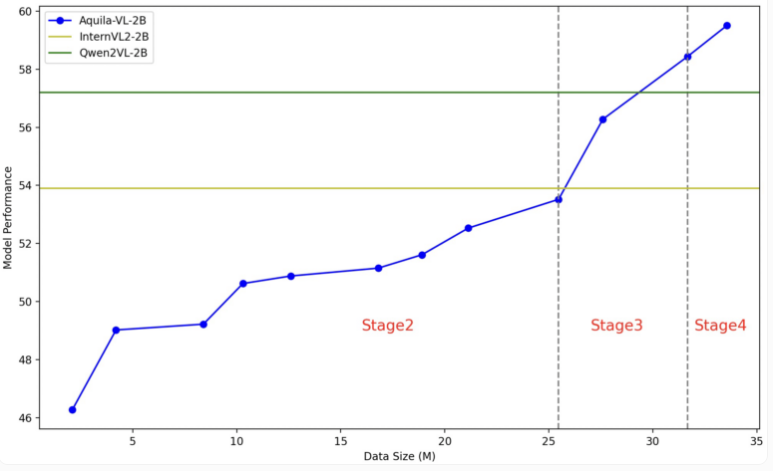
Aquila-VL-2B模型基于LLaVA-OneVision架构,使用Qwen-2.5作为语言模型,并采用SigLIP进行图像处理。模型的训练分为四个阶段,逐步提高复杂性,从基本的图像-文本关联到整合合成生成的数据。在多模态理解的MMStar基准测试中,Aquila-VL-2B以54.9%的得分领先,尤其是在数学任务中,该模型在MathVista测试中得分达59%,远超同类系统。
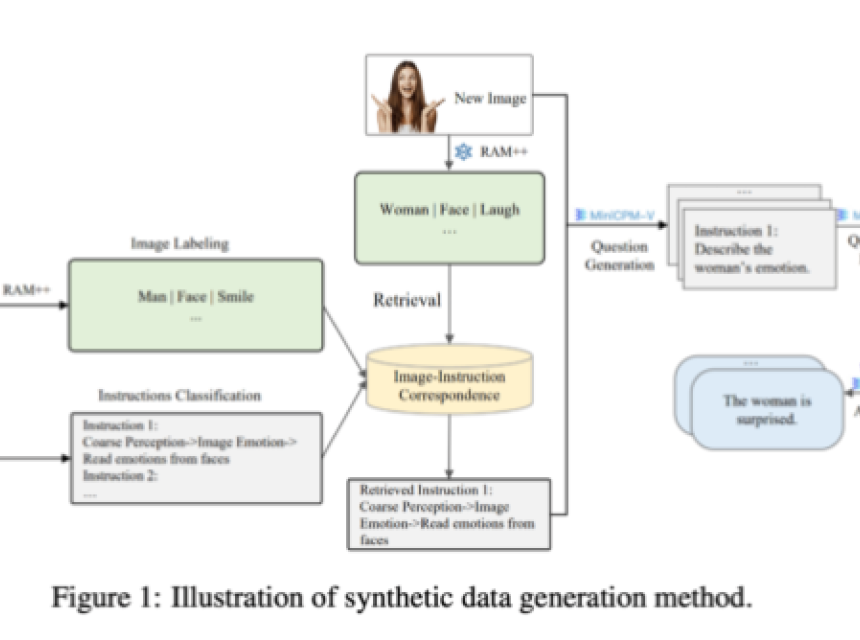
合成数据的重要性与开源模型的崛起
Aquila-VL-2B的成功,特别是在合成数据的使用上,显示了开源模型在AI研究中的崛起。合成数据的加入显著提升了模型的表现,若不使用这些额外数据,模型的平均表现将下降2.4%。这一发现与全球AI研究的趋势相吻合,即开源模型正在迎头赶上传统的闭源系统,尤其是在利用合成训练数据方面展现出良好的前景。
结论与展望
“Infinity-MM”数据集和Aquila-VL-2B模型的推出,不仅是中国在AI领域的一项重要成就,也是全球AI研究的一个里程碑。这一成果不仅展示了开源模型的潜力,也为未来AI技术的发展提供了新的方向。随着数据集和模型向研究社区的开放,我们期待看到更多的创新和突破,进一步推动AI技术的进步。
免责声明:除原创作品外,本平台所使用的文章、图片、视频及音乐属于原权利人所有,因客观原因或会存在不当使用的情况,如,部分文章或文章部分引用内容未能及时与原作者取得联系,或作者名称及原始出处标注错误等情况,非恶意侵犯原权利人相关权益,敬请相关权利人谅解并与我们联系。