

开源Moonshine语音识别模型:速度比OpenAI的Whisper快五倍
美国初创公司Useful Sensors开发了Moonshine,这是一款开源语音识别模型,处理音频的效率超过了OpenAI的Whisper,同时使用更少的计算资源。Moonshine专为资源有限的硬件上的实时应用设计,其主要优势在于灵活的架构。
主要特点
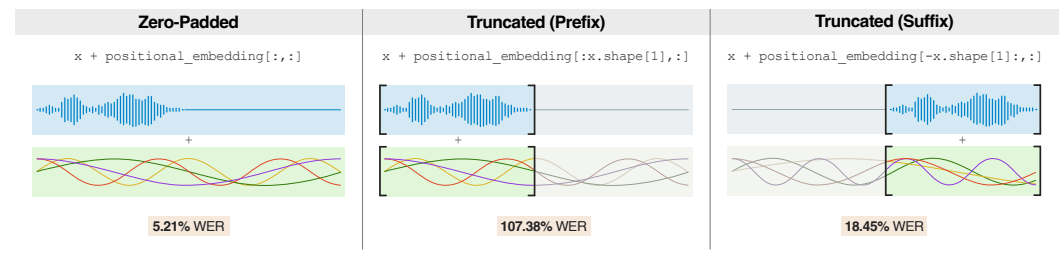
动态处理时间:与Whisper固定处理30秒音频片段不同,Moonshine根据实际音频时长调整处理时间,使其在处理较短音频时特别高效。
模型大小:Moonshine提供两个版本:小型Tiny版本拥有2710万个参数,而大型Base版本则有6150万个参数。相比之下,OpenAI的Whisper模型参数更多,Tiny版本为3780万个参数,Base版本为7260万个参数。
性能表现:测试显示,Moonshine的Tiny模型在准确性上与Whisper相当,但在计算能力消耗上更具优势。在不同音频水平和背景噪音的测试中,Moonshine的两个版本都保持了低于Whisper的字错误率(WER)。
离线能力与应用前景
Moonshine能够高效运行而无需互联网连接,这为之前由于硬件限制而无法实现的应用打开了新局面。与需要标准计算机的Whisper相比,Moonshine适用于智能手机和树莓派等小型设备。Useful Sensors将Moonshine应用于其英语-西班牙语翻译器Torre。
未来改进方向
尽管Moonshine在语音识别基准测试中略胜于Whisper,但在处理非常短的音频片段(少于一秒)方面仍有改进空间。研究人员建议增加更多短音频片段的训练数据,以提升模型在此类音频上的表现。
开源代码
Moonshine的代码已在Github上发布,用户可以自由访问和使用。需要注意的是,像Whisper这样的AI转录系统可能会出现幻觉现象,研究表明Whisper在处理有言语障碍的人时错误率较高。
免责声明:除原创作品外,本平台所使用的文章、图片、视频及音乐属于原权利人所有,因客观原因或会存在不当使用的情况,如,部分文章或文章部分引用内容未能及时与原作者取得联系,或作者名称及原始出处标注错误等情况,非恶意侵犯原权利人相关权益,敬请相关权利人谅解并与我们联系。